Eight journals over eight decades: a computational topic-modeling approach to contemporary philosophy of science
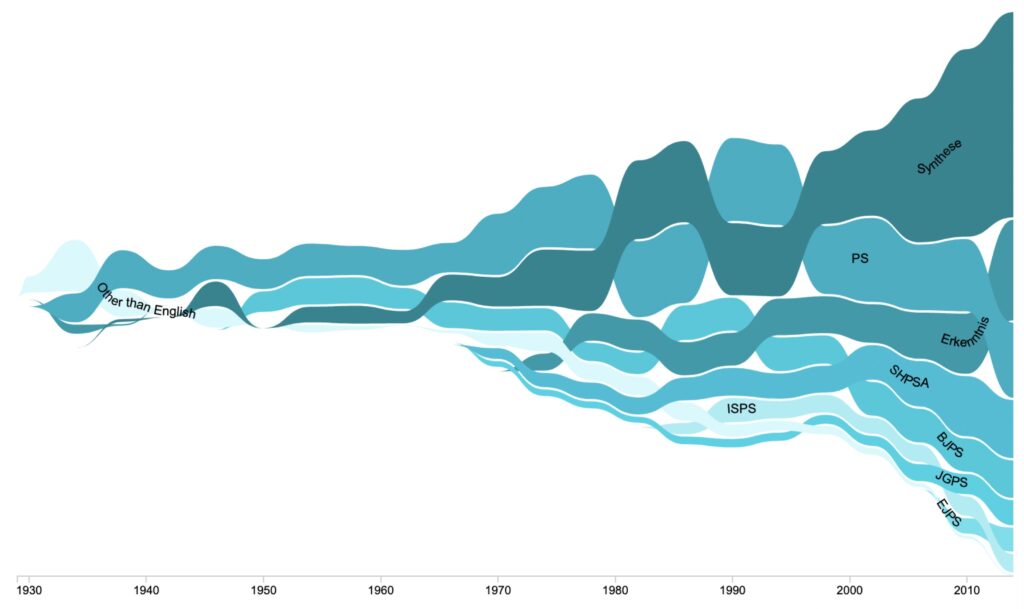
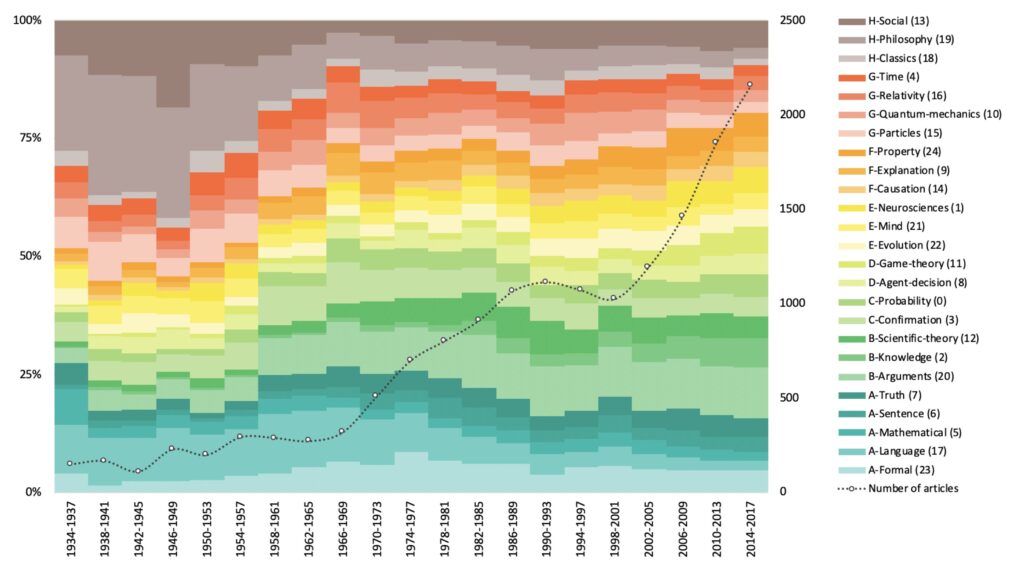
Computational approaches are extremely helpful to analyze large corpora and extract meaningful semantic information. In a previous paper, we characterized the journal Philosophy of Science through topic-modeling analyses (Malaterre, Chartier, and Pulizzotto 2019, see https://www.journals.uchicago.edu/doi/abs/10.1086/704372 or https://www.researchgate.net/profile/Christophe_Malaterre). Here we examine a much broader and comprehensive corpus composed of the full-text content of 15 897 articles published by eight philosophy of science journals from the 1934 up until 2017. These journals, which are among the most recognized journals that publish general philosophy of science research in English language, include: the British Journal for the Philosophy of Science, the European Journal for the Philosophy of Science, Erkenntnis, International Studies in Philosophy of Science, Journal for General Philosophy of Science, Philosophy of Science, Studies in History and Philosophy of Science (Part A), and Synthese. The results of our analyses document, in particular, the shift in topics in the philosophy of science, with a relative decrease of philosophy of language, logic and philosophy of physics articles over eighty years, and an increase in epistemology, philosophy of biology and of mind. Such quantitative data offer an empirical basis for what might otherwise be informal claims about the discipline and its evolution in the past eight decades as reconstructed from the perspective of its major journals. They are also the type of data that may trigger novel discussions about the directions the field might take.

Cite as: Malaterre, Christophe, Francis Lareau, Davide Pulizzotto, Jonathan St-Onge (2020) « Eight journals over eight decades: a computational topic-modeling approach to contemporary philosophy of science« , Synthese https://doi.org/10.1007/s11229-020-02915-6
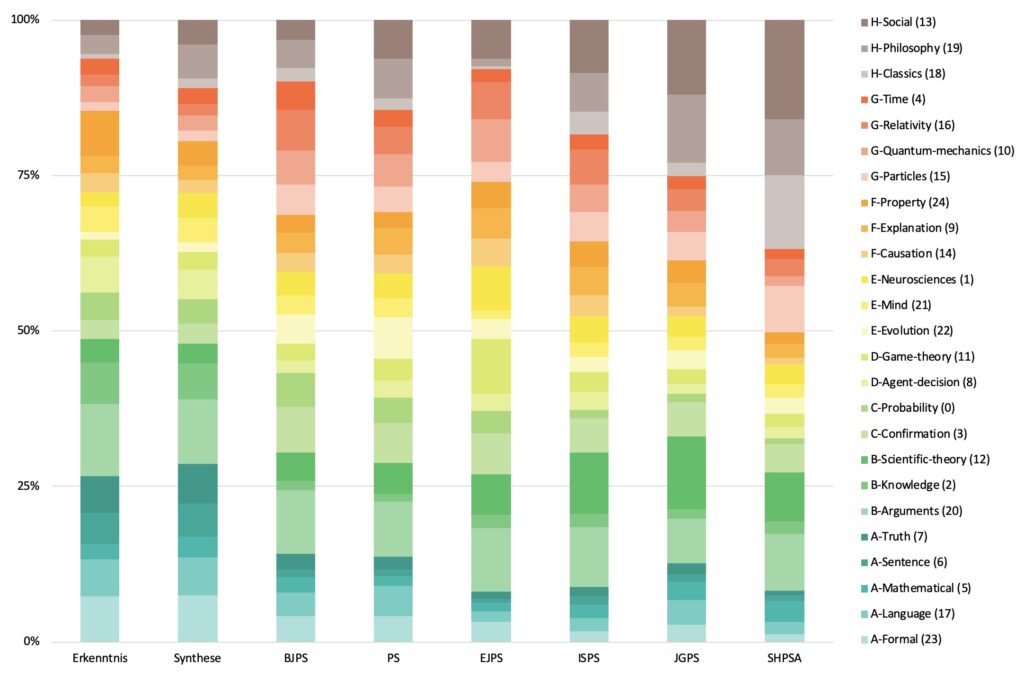
Visualization interface. This website makes it possible to explore the different topics, their keywords and the articles in which they are present. Formally, topics that result from topic-modeling computational approaches—such as the one we implemented here—are probability distributions over words. The semantic content of topics can thus be inferred by examining the words that have the highest probabilities to be present in a given topic. We have attributed meaningful labels to topics in this way. The methods also make it possible to retrieve the documents in which the topics are the most probable. Examining these documents also helps in inferring the semantic content of topics. The topic-model includes 25 topics that were grouped into 8 clusters (A through H) with the assistance of a community detection algorithm. Browsing on the website, one can view the detailed content of all 25 topics, as well as the articles in which they are the most probable. Diachronic views are also available that reveal topic trends over time, on a yearly basis. Topic labels all have the form: « N-Name (XX) », for instance « B-Scientific-theory (12) », where N is the category letter, Name is the name we gave to the topic following its interpretation and XX is the topic ID (a number given by the topic-modeling algorithm, that makes it easier to retrieve computational information about the topic). Interface realized by Martin Léonard.
Acknowledgements: The authors are grateful to JSTOR, Elsevier, Oxford University Press, Springer, Taylor and Francis, and University of Chicago Press for providing access to journal articles for text-mining purposes. Funding from Canada Foundation for Innovation (Grant 34555), Canada Social Sciences and Humanities Research Council (Grant 435-2014-0943) and Canada Research Chair (CRC-950-230795) is gratefully acknowledged. FL acknowledges support from the Fonds de recherche du Québec – Société et culture (Grant 276470).